
Over the years I realized my main two passions being distributed systems and artificial intelligence, and I am lucky to have experienced that in both research with multi-agent systems and industry throughout the Big Data hype. I consider myself as the bridge between those data engineers looking at infrastructural aspects, and the pure data scientists who are focused on the mathematical aspects. I deliver production-ready use cases that add value to their data or infrastructure, while considering performance and system-oriented aspects. Somebody calls this position DataOps or Machine Learning Engineer. If you are still in doubt, I invite you to read this nice post about the gap between Data Scientists and Data Engineers, as well as more about DataOps.
Since November 2021, I am a Sr. Big Data and Personalization Engineer at Chili Tech, the technical team powering chili.com a major European OTT video-on-demand provider. The team served analytics for various customers: Chili.com, Itsart.tv and Fifa+, having different business models, spanning from transactional (TVOD), to advertising-based (AVOD) and subscription- based (SVOD) video on demand.
The team worked on a shared kappa architecture to deliver reports and dashboards, as well as serve data for specific use cases. My main interest were personalization use-cases:
- (Real-time) Content/User Feature Extraction
- Recommender systems - item-item collaborative such as "selected for you" and "other users also bought", and content-based "similar to this", "continue watching", genre-based and community-based (e.g. trending)
- Dense retrieval for content-similarity and semantic search
- Personalized ranking and page composition
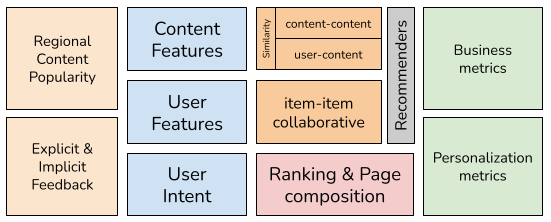
Being a full remote product company, the focus has always been code quality and performance. In spite of the "Big Data and Personalization" team being rather small (≃ 7 people), we employed pair programming and test-driven development (TDD).
In the period June 2019 to November 2021 I have been with Leithà, the data lab of the Unipol group, a major Italian insurance.
With about 4.5 Millions connected black boxes, the company is the European leader in the vehicle telematics market, as well as the main Italian player and second in the world by a little (here).
There I have been designing end-to-end data products running on-premise on the Cloudera Hadoop and ⎈Kubernetes Openshift ecosystems. More specifically, I worked on both batch and streaming analytics on user, GIS and vehicle telematics data for use cases related to risk calculation and in-app value-added services, such as:
- Pricing: Spatio-temporal modeling of traffic and crash conditions; Extraction of user-related driving KPI for tailored pricing; Design of a Feature Store for online serving (HBase) and offline historization for training and point-in-time join (HDFS);
- Real-time crash classification for automated claim management; Continuous stream monitoring with application-specific metrics. Design of a Feature Store as hierarchy of libs for payload definition, feature extraction, model description, to be used for training (Python) and serving (Java, Scala);
- Data Operations (#dataops): Discovery (description and crawling of sources), Quality (enforcement of pre/post computation constraints and monitoring), Protection (masking and encryption for historization), Versioning (data and model lifecycle management and lineage control);
- ML Operations (#mlops): Conception and setup (via gitops tools) of on-prem DS environment to integrate existing K8s- and Hadoop-based envs and enforce guidelines for data preparation, feature extraction and management, model training and serving; Achieved by definition of templates and recipes, e.g. for submitting Spark apps or scheduling workloads. Eventually acting as a tech lead in the area of MLOps.
Previously, I was with Data Reply GmbH (Reply AG) in München (Germany) as a Data Science & Engineering consultant, and I mainly worked with the Confluent (Kafka, Kafka connect, Kafka Streams) and Hadoop (Hadoop, Hive, Impala, Hue, Spark, HBase, Ooozie, Sqoop) ecosystems, both on on-premise (i.e., cloudera, hortonworks) and on-cloud (mainly AWS and Azure) infrastructures. The company has a focus on Big Data Science and Engineering. Beyond the hype, what I did was to design software artefacts for large-scale computing clusters, which can run AI algorithms on massive datasets in order to deliver business insights and services.
Among the successfully completed projects:
- Asset Replacement Optimization: priorization of medium voltage cables and substations to prevent outages (Azure cloud, PySpark, Scikit-learn, Gitlab CI, Docker/Kubernetes). This includes both explorative data analysis of SAP, GIS and outage databases, as well as the industrialization of existing pyspark/scikit learn code extracting the models.
- Fraud Detection: unsupervised identification of likely fraudolent behavior from Conviva set-top-box data (Spark, Kafka-Connect). This included mainly the industrialization of Java Spark code, as well as the setup of two new Kafka connectors to ingest Conviva data.
- Customer Segmentation: scaleout of pyspark code doing k-means-based basket analysis (PySpark). This included test automatization of existing PySpark code and the finetuning of Spark runtime parameters.
- Anomalous Energy Demand Alerting: ARIMA-based early detection of demand peaks for large energy consumers (Spark, AWS)
- CP 360: processing of usage logs and catalogue information to build a customer 360 querable view (Java Spark Streaming, HBase, Hive, Oozie, Ansible)
- Automated Business reporting for Financial Department (Oozie, Hive, Kafka, Kafka-connect, Ansible)
- Setup of Ingestion connectors for a Data Lake, mostly JDBC, HDFS, Couchbase, HTTP, Logs, FTP (Sqoop, Kafka, Kafka-connect, Ansible)
Previously, I have been IT Consultant for Smart Energy solutions at Power Reply GmbH (Reply AG). There I worked on mobile energy analytics projects with German energy utilities, focusing mostly on Android development and REST/JSON web services running on the Spring framework. I focused on demand-related analytics, specifically empowered by load disaggregation and mostly targeted to residential customers. This included:
- Load Disaggregation App for residential customers (Android, Spring, Spring boot), where I worked on event detection from outlet data, initially implemented in Python/Scikit-learn and then converted to a batch Spring task writing the results to PostgreSQL; The events are used as ground truth in a pilot study, and a set of metrics are periodically calculated and shown on a jquery dashboard to assess the third-party load disaggregation component used to identify the device events out of the aggregated power signal.
- Mobile App for energy related value-added services, mainly to have all billing and historical consumption and production information displayed, as well as location-based services, such as coupons. The use of Crashlytics and Google analytics allows for the tracking of the application usage and a quick bug fixing, as well as user modeling. (Android, REST backend, Crashlytics, Google Analytics)
Until January 2016, I have been doing research on power trading and brokerage for Microgrids, supported by a research scholarship funded by the Alpen-Adria-Universität Klagenfurt. I eventually defended my PhD dissertation in September 2016.
During my PhD I have been with the Lakeside Labs, a research cluster focusing on self-organising systems, namely working for the MONERGY Interreg IV project and the Smart Grid Lab. There I worked on intelligent energy applications in Smart homes, namely on solutions to improve energy awareness and facilitate the integration of renewable energy generation.
In June 2012, I received a Master in Computer Science from Reykjavik University (Iceland) and University of Camerino (Italy). During my first year in Camerino, I focused on distributed and multi agent systems. I spent my second year at Reykjavik University in Iceland. I am a former student of the Center for Analysis and Design of Intelligent Agents (CADIA), where I wrote my thesis and I attended courses on Artificial Intelligence. My project dealt with the implementation of an Early Warning System for Ambient Assisted Living, basically a context-aware agent that, given a description of the environment as input, is able to autonomously evaluate the danger level of states and prevent users from getting too close to such dangers. Together with other 7 recipients, I was awarded for this project the best MS thesis award by the Marche regional government.
In 2010, I graduated as a B.S. in Applied Computer Science with focus on Embedded Systems at "Carlo Bo" University of Urbino. I have attended courses for designing embedded systems (e.g. digital electronics, electronic design automation, architectures and communication), as well as multimedia systems (e.g. multimedia processing, languages and applications, Information Systems). My final project concerned the use of Contiki OS for measuring environmental parameters in internet-of-things applications.
In 2009, I spent 3 months as intern software engineer for Townet, a leading company in wireless broadband networks in the ISM band. In this period, I had the chance to participate to the complete hardware and software development process and get an overall understanding of startup companies. Previously, I have worked as intern for companies involved in electronics and automation (ATE Elettronica), as well as web development (Lyn-X).
Tweet

Are you sure you want to delete your account?
Insert a new password:
Insert the user email and his privileges: